|
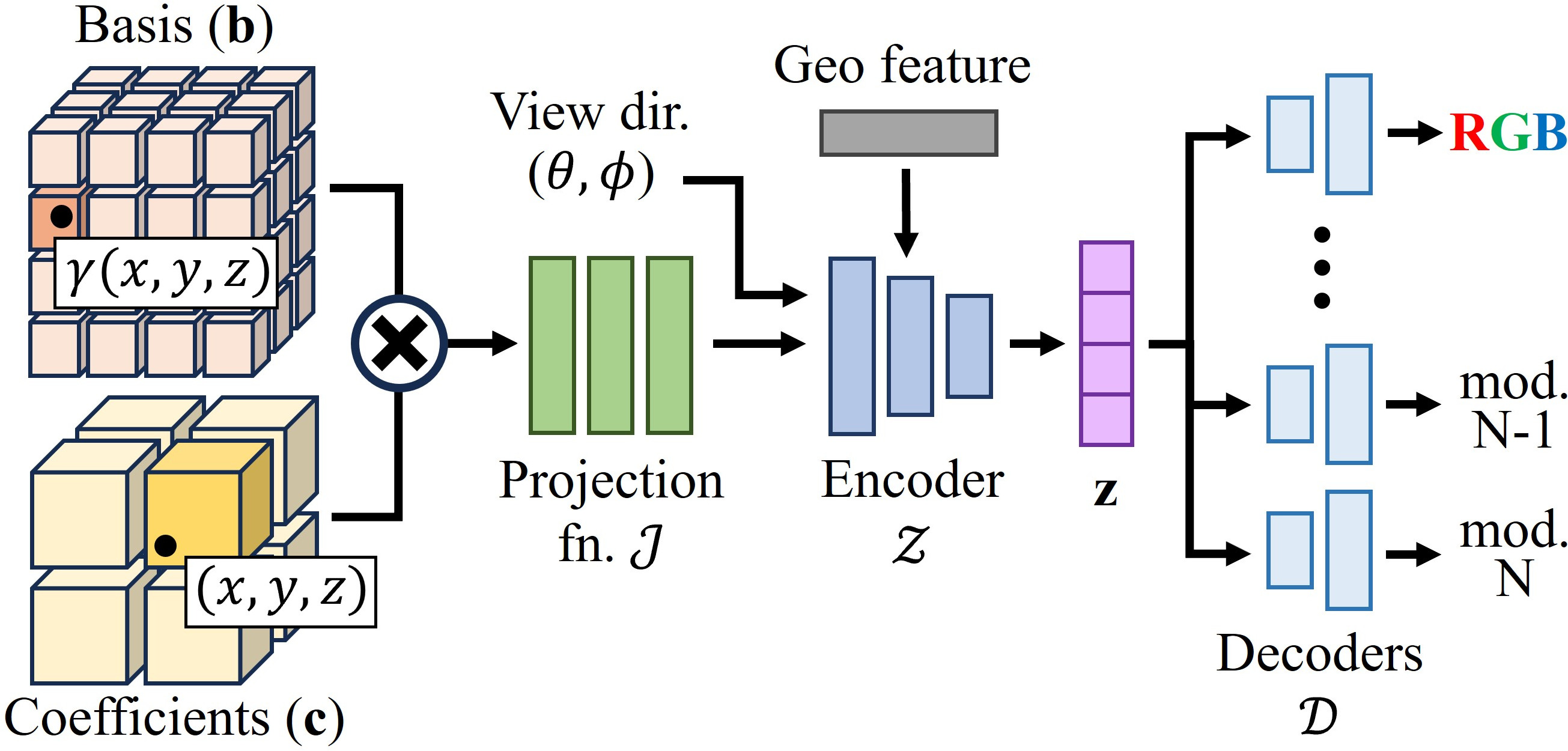
SPoILeR builds on the MultimodalStudio NeRF-based radiance module and replaces its multi-resolution hash-grids with two sets of learnable feature grids, inspired by Dictionary Fields: a basis field and a coefficient field.
The basis field, together with a shared projection function, latent encoder, and per-modality decoders, is common to every scene and stores the mutual correlation between imaging modalities. The coefficient field is instead optimized independently for each scene and captures its specific geometry and radiance properties, such as textures and reflections.
|
|
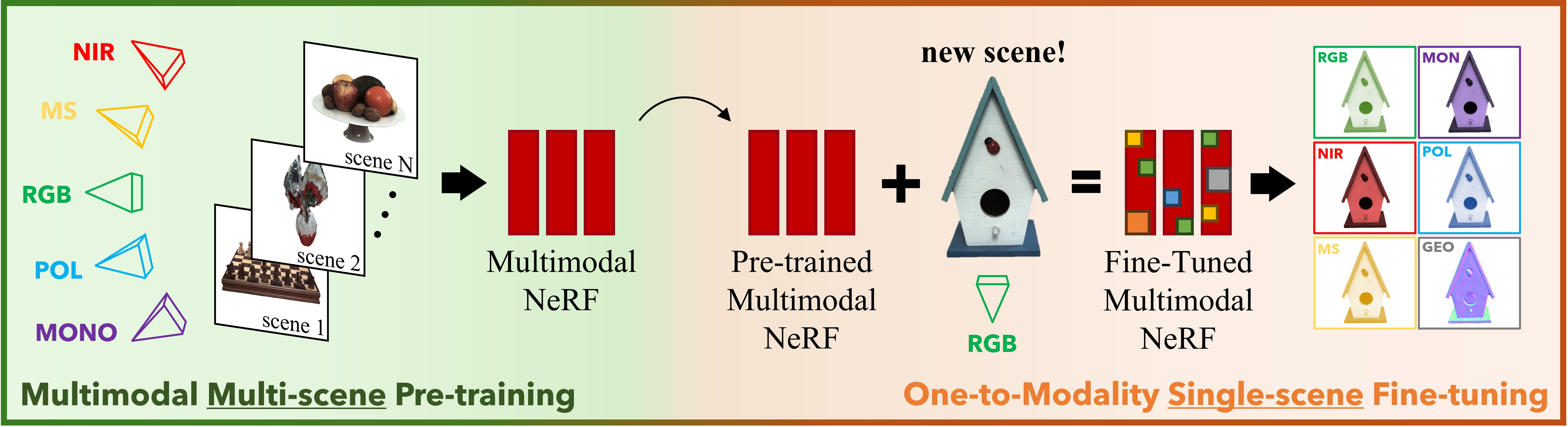
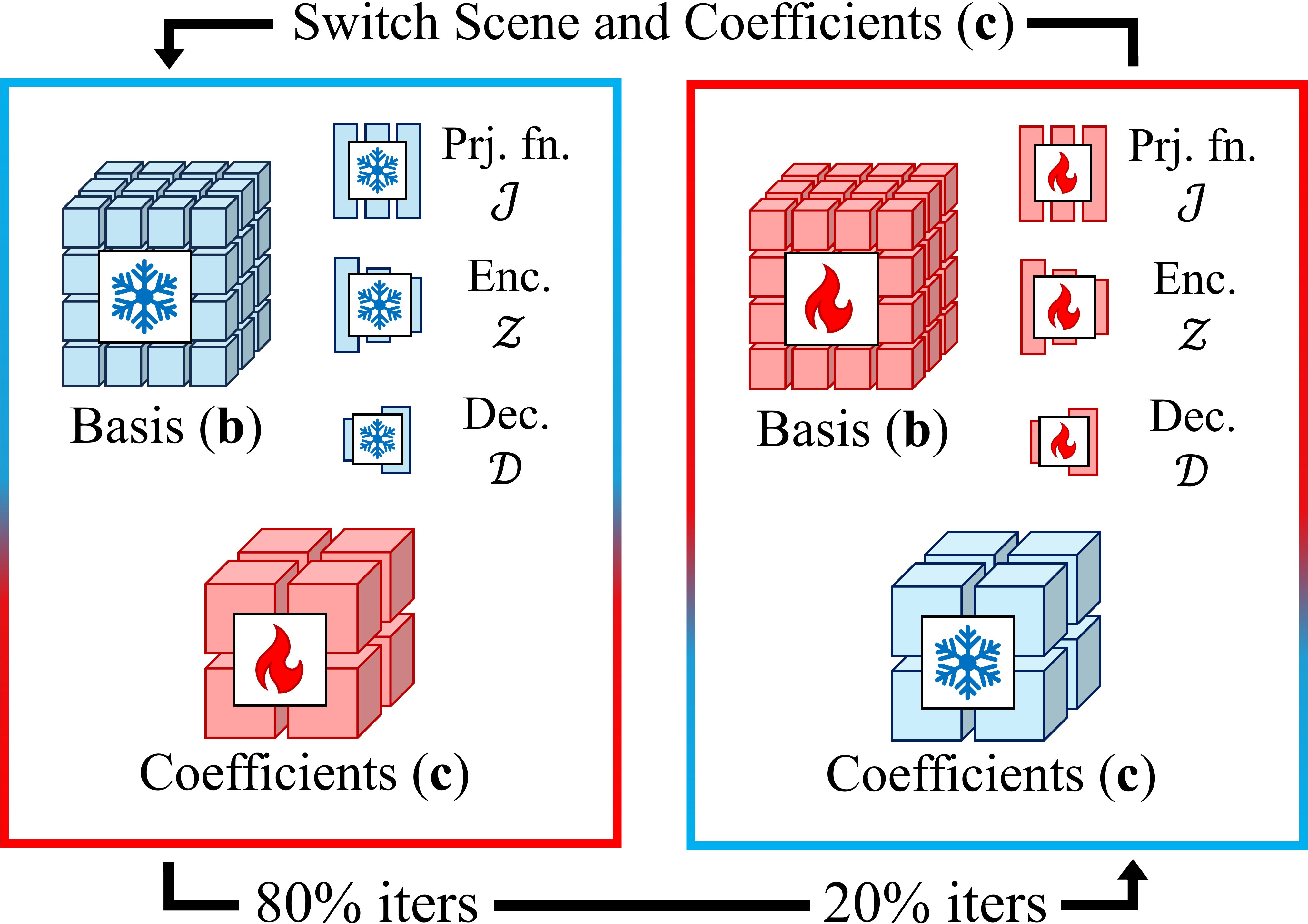
SPoILeR is trained in two stages. During pre-training, the model observes several multimodal multi-view scenes and alternately freezes the shared modules and the scene-specific modules on a fixed schedule, letting the shared modules learn a general multimodal radiance prior while every scene keeps its own coefficients.
During fine-tuning, the shared modules are frozen and only the coefficient field and geometry of the new scene are optimized. Because the new scene may only provide RGB supervision, the pre-trained shared modules supply the missing multimodal knowledge, enabling photorealistic and multi-view consistent renderings of modalities never captured for that scene — with a much smaller and faster optimization than training a model from scratch.
|
Training with limited multimodal supervision makes the latent radiance space prone to diverging for the unobserved modalities. SPoILeR introduces three regularization losses that keep the multimodal latent space robust, explainable, and consistent between pre-training and fine-tuning.
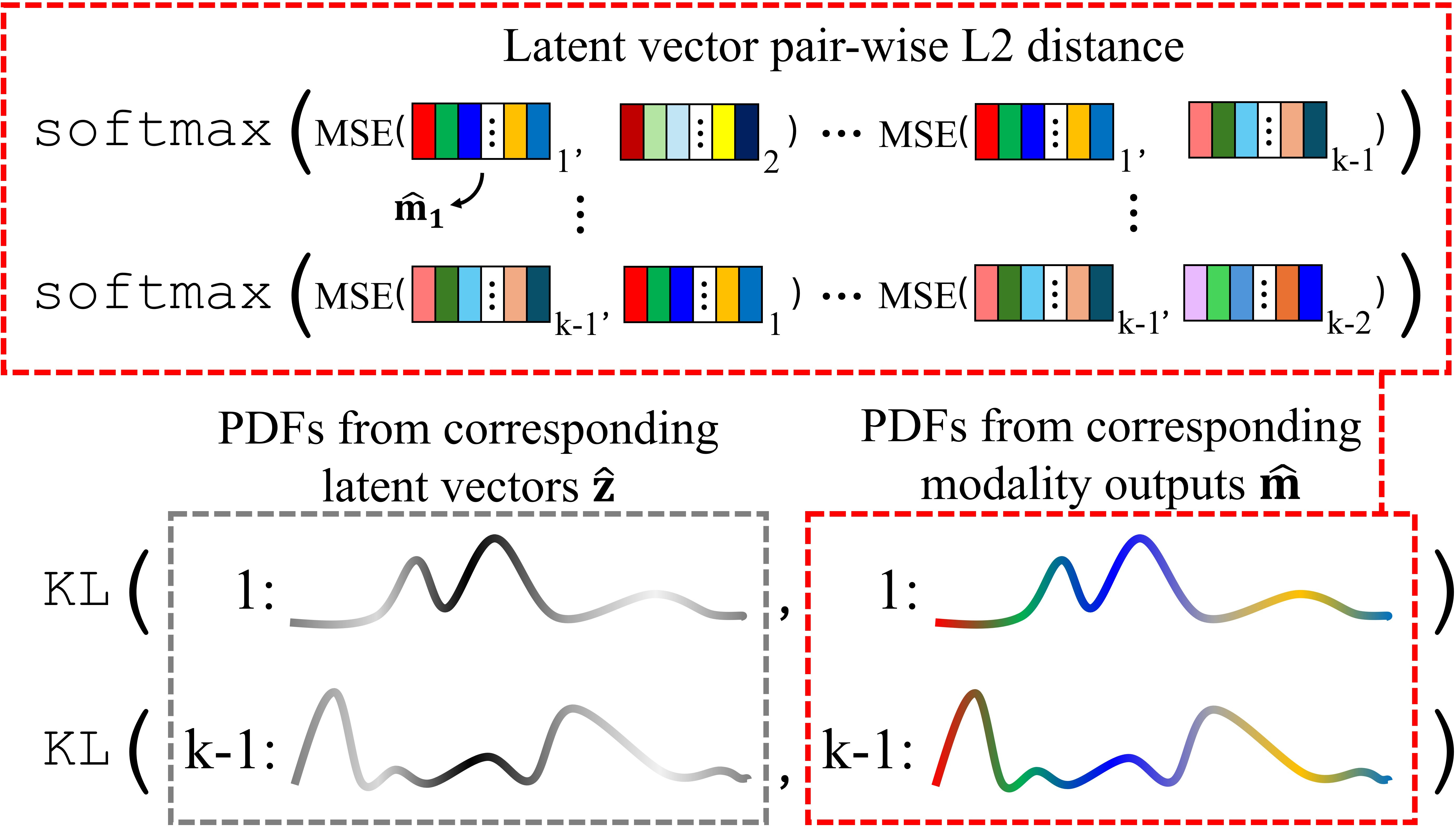
|
Latent Space Geometry Loss. Encourages the pairwise distances between latent vectors to mirror the pairwise distances between the corresponding decoded multimodal radiance values, so that small latent shifts do not produce unpredictable jumps in the rendered radiance. It is only applied during pre-training, while the multimodal latent geometry is being formed.
|
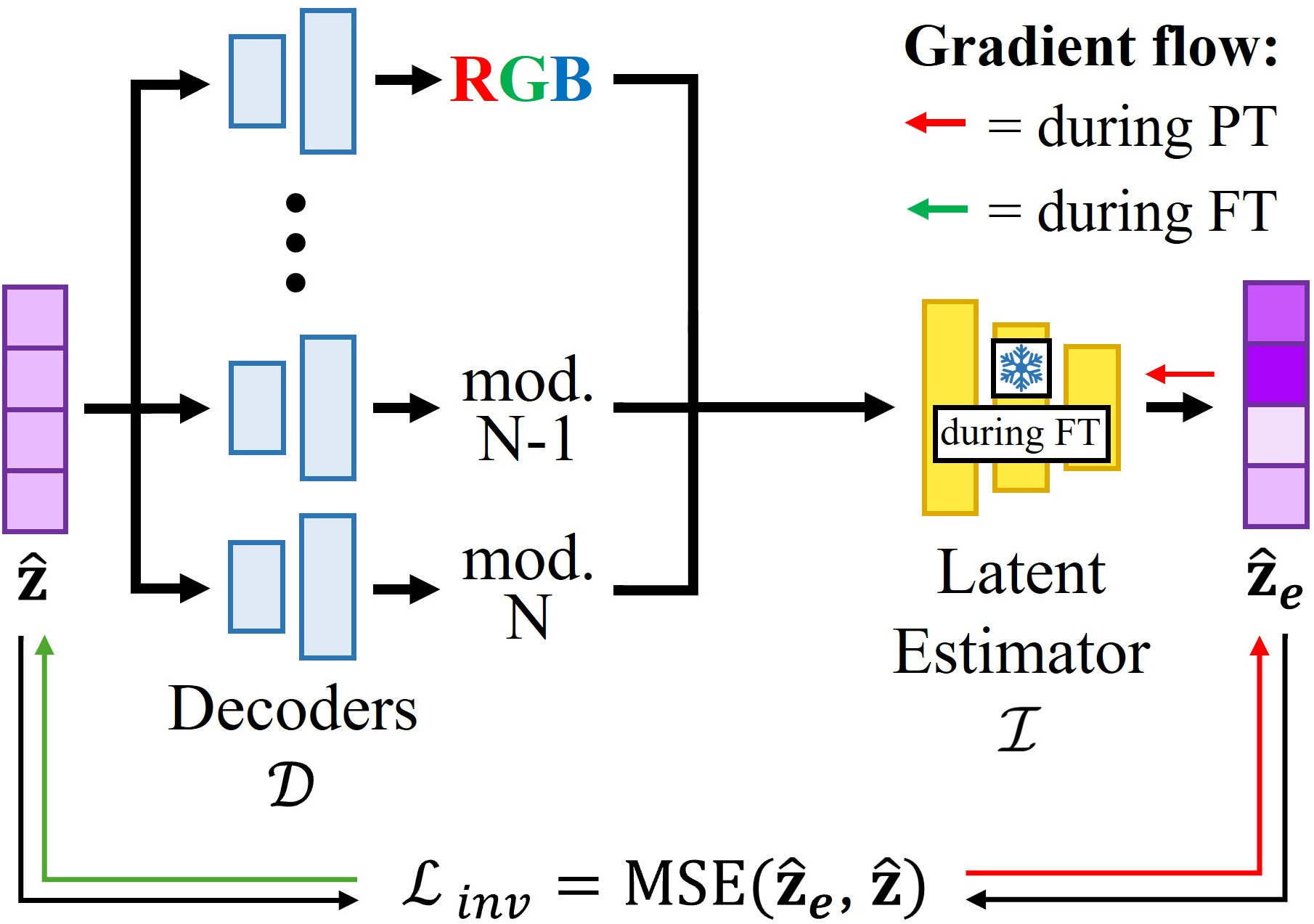
|
Inverse Function Loss. A small MLP is trained during pre-training to invert the decoding process, mapping decoded multimodal radiance values back to the latent vector that produced them. Kept frozen during fine-tuning, it provides a target that keeps the fine-tuned latent space consistent with the one learned during pre-training, preventing the correlation between modalities from being forgotten.
|
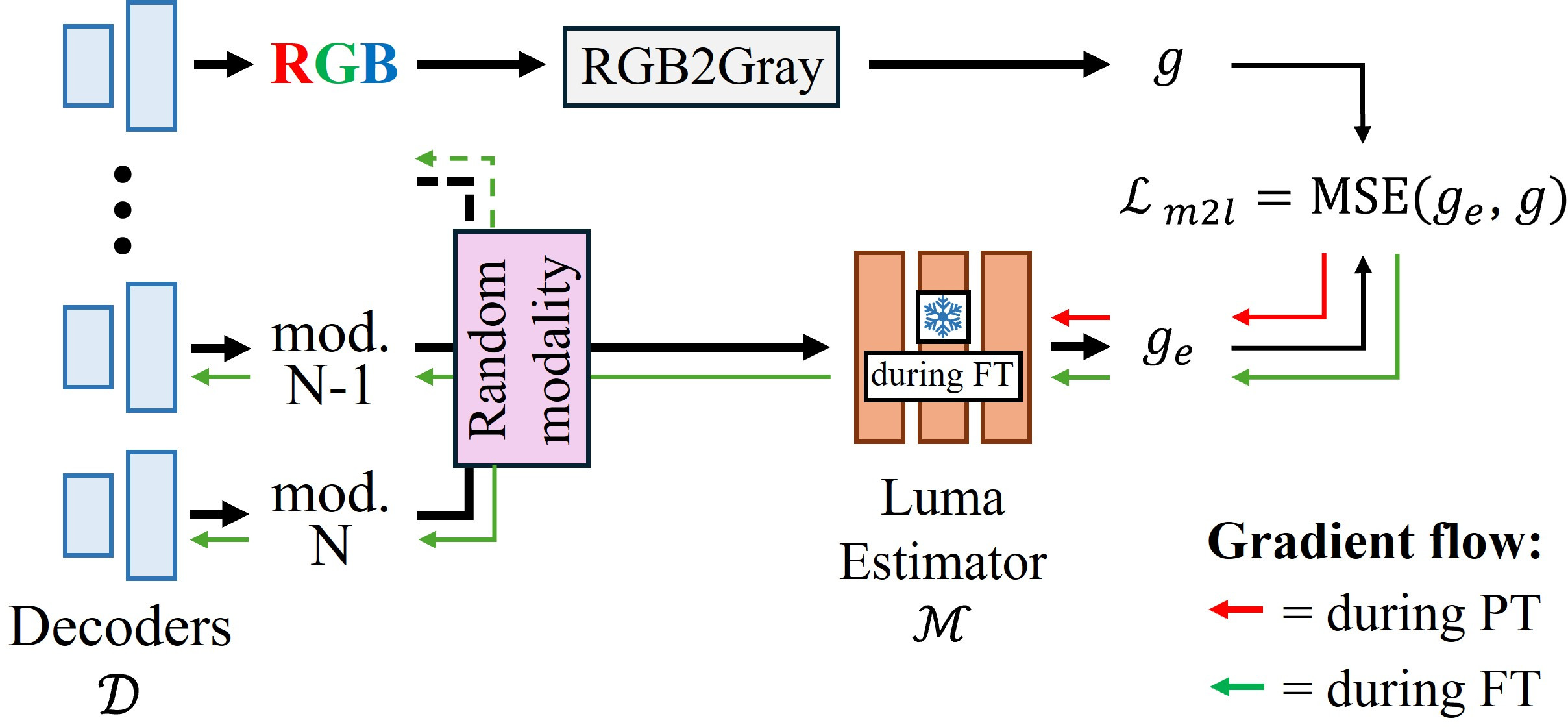
|
Modality-to-luma Loss. A second small MLP learns, during pre-training, to predict the RGB luminance that corresponds to any modality's radiance values. Used frozen during fine-tuning, it nudges modalities that partially overlap with the visible spectrum — such as Mono, NIR, and Pol — to stay correlated with RGB, which is especially important for Mono and NIR renderings.
|
SPoILeR (Ours) is fine-tuned using RGB supervision alone and compared with MultimodalStudio (MMS-FW), trained from scratch on the same scene with the same single-modality supervision. Despite having 3× fewer parameters and a 4× shorter fine-tuning time, SPoILeR matches MMS-FW on the supervised RGB modality and, more importantly, is the only method able to render photorealistic views of Mono, NIR, Pol, and MS — which MMS-FW simply cannot produce without their own captured frames. When both methods are supervised by every modality (upper bound), MMS-FW's larger from-scratch capacity gives it an edge of about 2 dB PSNR, while SSIM remains comparable.
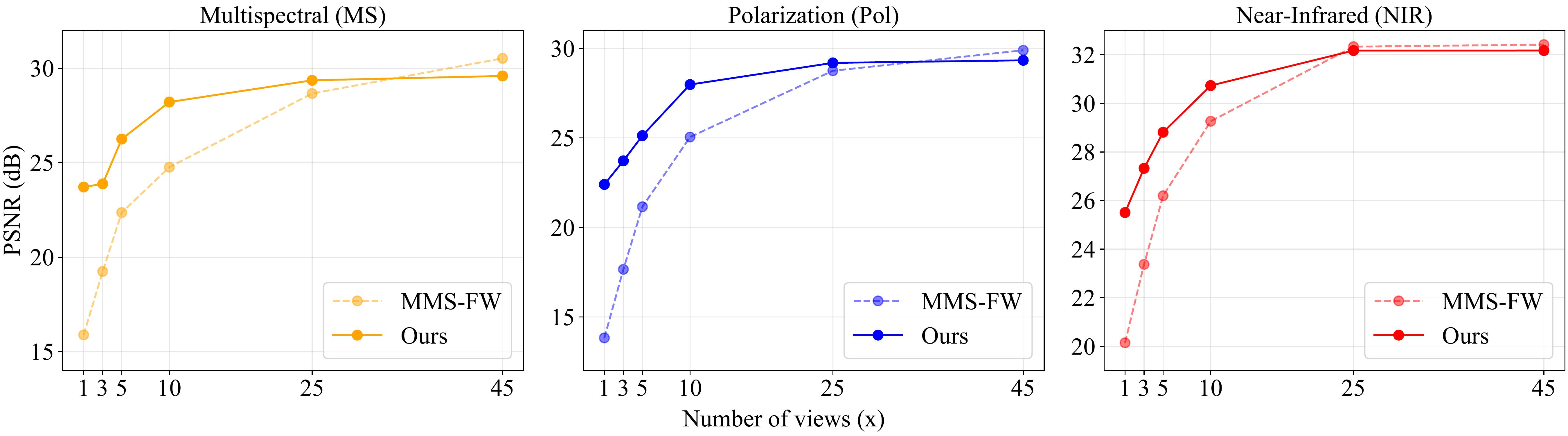
Let's consider a scenario with an unbalanced number of frames per modality: 45 RGB frames are always available, while the second-modality (MS, Pol, or NIR) frames are reduced to 1, 3, 5, 10, or 25.
SPoILeR clearly outperforms MMS-FW, particularly with few second-modality frames. With just a single MS, Pol, or NIR frame, SPoILeR achieves gains of ∼8, ∼7, and ∼6 dB PSNR, respectively, and it still holds a ∼2.5 dB advantage with 10 frames — MMS-FW only matches SPoILeR's performance once 25 frames are available.
These results confirm that the pre-trained multimodal prior lets SPoILeR make the most of very limited additional-modality supervision.
Feed-forward RGB-to-modality conversion networks such as MST++ (for multispectral) and PolarAnything (for polarization) can be combined with a standard NeRF by first converting each RGB frame and then training on the converted frames. However, since these networks operate on a single view at a time, their outputs are not multi-view consistent, and this inconsistency propagates into the trained radiance field. In contrast, SPoILeR's fine-tuning is grounded in a multimodal prior learned jointly across many 3D scenes, and clearly outperforms this two-stage strategy.
SPoILeR outperforms MMS-FW coupled with MST++ by 3.46 dB PSNR on MS, and MMS-FW coupled with PolarAnything by 14.08° / 0.044 on the polarization angle / degree errors, confirming its reliability as the current state of the art for multi-view consistent modality-to-modality conversion.
Every ablation leads to worse results. The modality-to-luma loss is the most impactful, particularly for Mono and NIR: these sensors also measure part of the infrared spectrum, so without this loss the model tends to decouple their representation from RGB. The inverse function loss plays a complementary role, anchoring the fine-tuning latent space to the correlations learned during pre-training across all modalities. Finally, the latent space geometry loss mostly benefits Pol and MS — the two modalities with the richest, most inter-correlated channels — by making the decoded radiance less sensitive to small latent perturbations.

|
| Mod. | Ours | w/o Llsg | w/o Linv | w/o Lm2l |
|---|
| RGB | 30.07 | 29.90 | 29.96 | 29.95 |
| Mono | 25.78 | 25.44 | 25.54 | 21.04 |
| NIR | 26.55 | 26.30 | 25.96 | 22.91 |
| Pol | 24.25 | 23.08 | 24.01 | 23.73 |
| MS | 25.45 | 23.14 | 25.28 | 25.36 |
PSNR (dB) of the RGB-supervised fine-tuning.
|